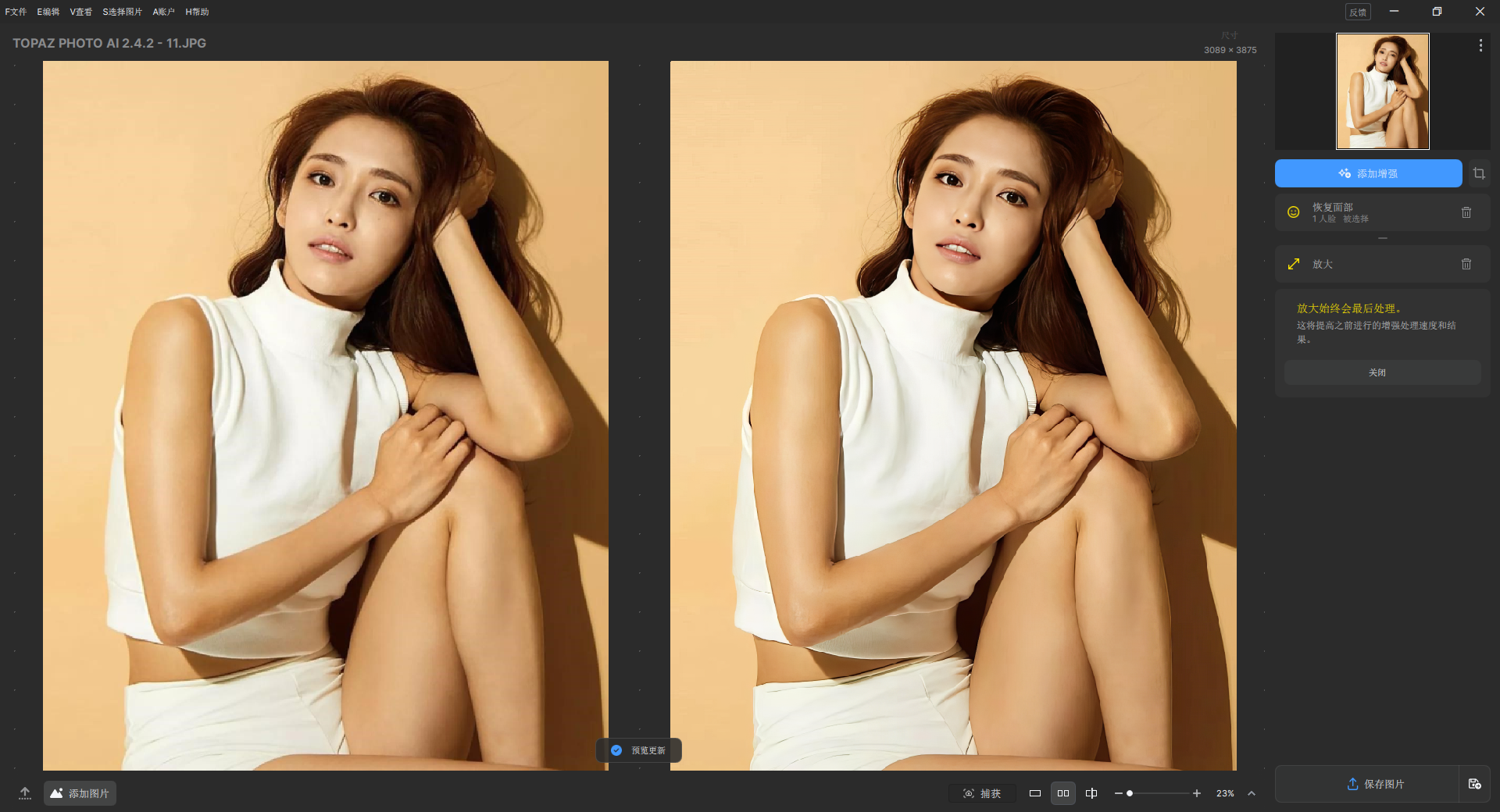
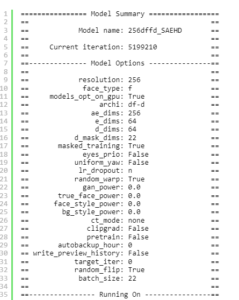
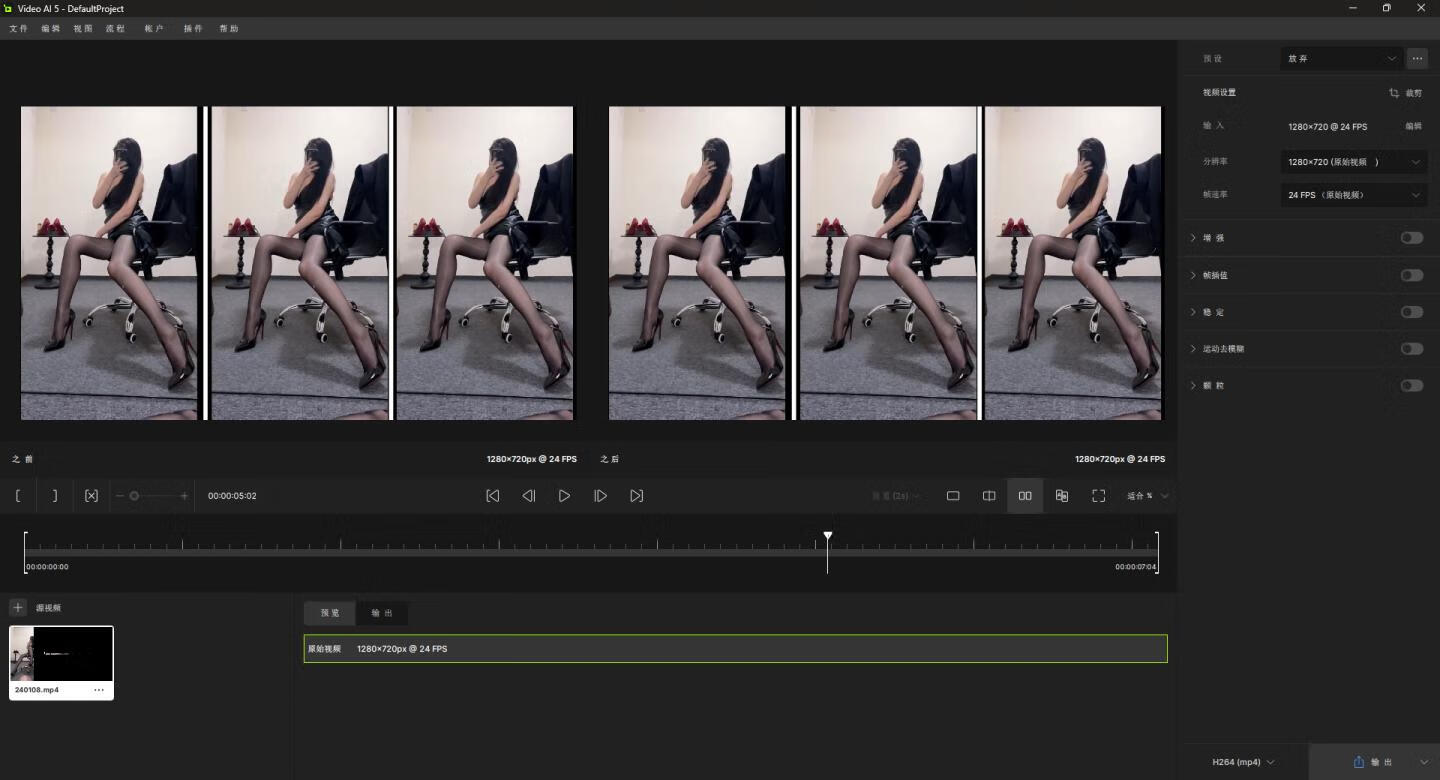
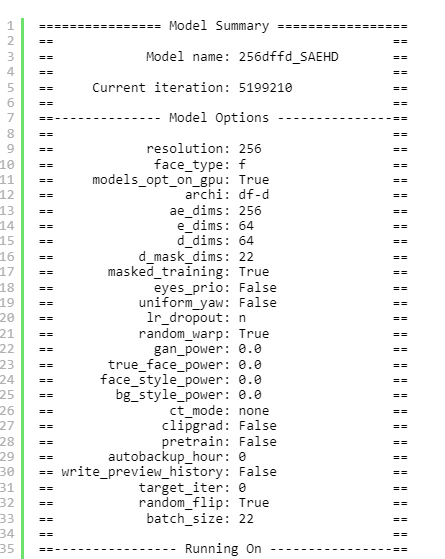
Step – Audio – EditX 是由阶跃星辰(StepFun)开发的全球首个开源 LLM 级音频编辑大模型,它基于 30 亿参数的 LLM 架构,凭借统一的 LLM 框架而非多模块拼接方案,实现文本驱动的音频创作,能精准控制音频的多种属性,在多个音频处理场景中都有着出色的表现,以下是其核心相关信息介绍:
这是由阶跃星辰(StepFun AI) 发布的首个开源、基于大语言模型(LLM)的音频编辑大模型 8。
你可以:
✅ 修改声音情感:支持“开心”、“悲伤”、“愤怒”等数十种情感标签,并可多次迭代增强或减弱强度 1
✅ 切换说话风格:一键变成“撒娇”、“耳语”、“老人”、“小孩”等十余种风格,还能叠加微调 1
✅ 插入副语言行为:智能添加“笑声”、“叹气”、“清嗓子”等自然语气词 1
✅ 零样本TTS:无需训练,输入文本即可生成高质量语音
![图片[1]-Step-Audio-EditX最新语音克隆-声音情绪调一键整合包-逃课猫Deepfacelab|AI智能研究站](https://wkphoto.bj.bcebos.com/9358d109b3de9c826faf15d97c81800a18d8439a.jpg)
核心功能
音频情感与风格细调:可对音频进行愤怒、开心等多种情感的增强或减弱编辑,也能实现撒娇、耳语、老人音等风格的叠加与微调,还支持多轮迭代编辑,逐步调整到理想效果。
副语言精准插入:能插入呼吸、笑声、叹气等 10 类自然副语言元素,像通过添加相关标签,让合成的音频更具自然感和感染力。
零样本 TTS 能力:无需目标人物语音样本就能克隆音色,且通过添加方言标签,可直接实现四川话、粤语等方言的切换,同时也支持中英文等多语言的语音克隆。
音频优化处理:具备降噪功能,能提升嘈杂音频的清晰度,此外还可对音频进行语速调整,满足不同场景下的音频播放需求。
典型应用场景
内容创作领域:可为短视频、广告、游戏生成多角色、多情绪配音,也能给有声书赋予不同角色风格的语音,增强内容表现力。
教育与服务领域:在语言学习中可生成不同口音语调的语音供模仿;还能将智能客服的平淡语音转为热情语气,搭配方言功能满足地域化服务需求。
音频修复场景:可对会议嘈杂录音做降噪、静音修剪处理,还能调整语速和添加情感,生成清晰易懂的会议纪要音频。
1、该资源仅供学习和研究传播,大家请在下载后24小时内删除,一切关于该资源商业行为与逃课猫智能研究站(taokemao.cn)无关。
2、请勿将该软件程序进行商业交易、转载、违法运营等行为,该软件只为研究、学习所提供,该软件程序使用后发生的一切问题与本站无关。
3、若本程序源/码侵犯了您的权益,请及时联系我们予以删除!
4、本程序仅供研究学习使用,切勿商用以及违法使用!
5、本站收费内容,只用于维持域名注册、网页空间租用等费用日常开销。
6、本站免费、含会员内容的软件工具,皆不包含人工技术服务教程等服务,大部份已提供视频教程,请自行网上搜索。