
教程分享共29篇
分享软件使用技巧
标签
排序

DeepFaceLab官方遮罩教程使用方法“ whole_face” + XSeg
这个是官方最标准的一个视频教程,建议新手认真观看,理解其中的内容,不要小看了哦。很多主要的都介绍了,虽然全程没有讲解。

AnyDoor 本地整合包,可一键换装
AnyDoor的主要功能是“图像传送”,就是将一张图像的内容融合到另外一张图像中,例如,将女生的蓝色短袖换成,其他样式的红色衣服。所以,也可以理解成“一键PS合成”或者PS中的内容感知移动工...

VideoReTalking中文一键整合包带完整视频教程
VideoReTalking是一个利用AI实现视频人物嘴型与输入的声音同步的创新技术。输入任意视频和音频, VideoReTalking可以生成一个人物嘴型与音频同步的新视频。这项技术不仅让嘴型与声音同步,还可以...
 会员专属
会员专属
本地部署自定义Ollama安装路径
由于Ollama的exe安装软件双击安装的时候默认是在C盘,以及后续的模型数据下载也在C盘,导致会占用C盘空间,所以这里单独写了一个自定义安装Ollama安装目录的教程。Ollama官网地址:https://olla...
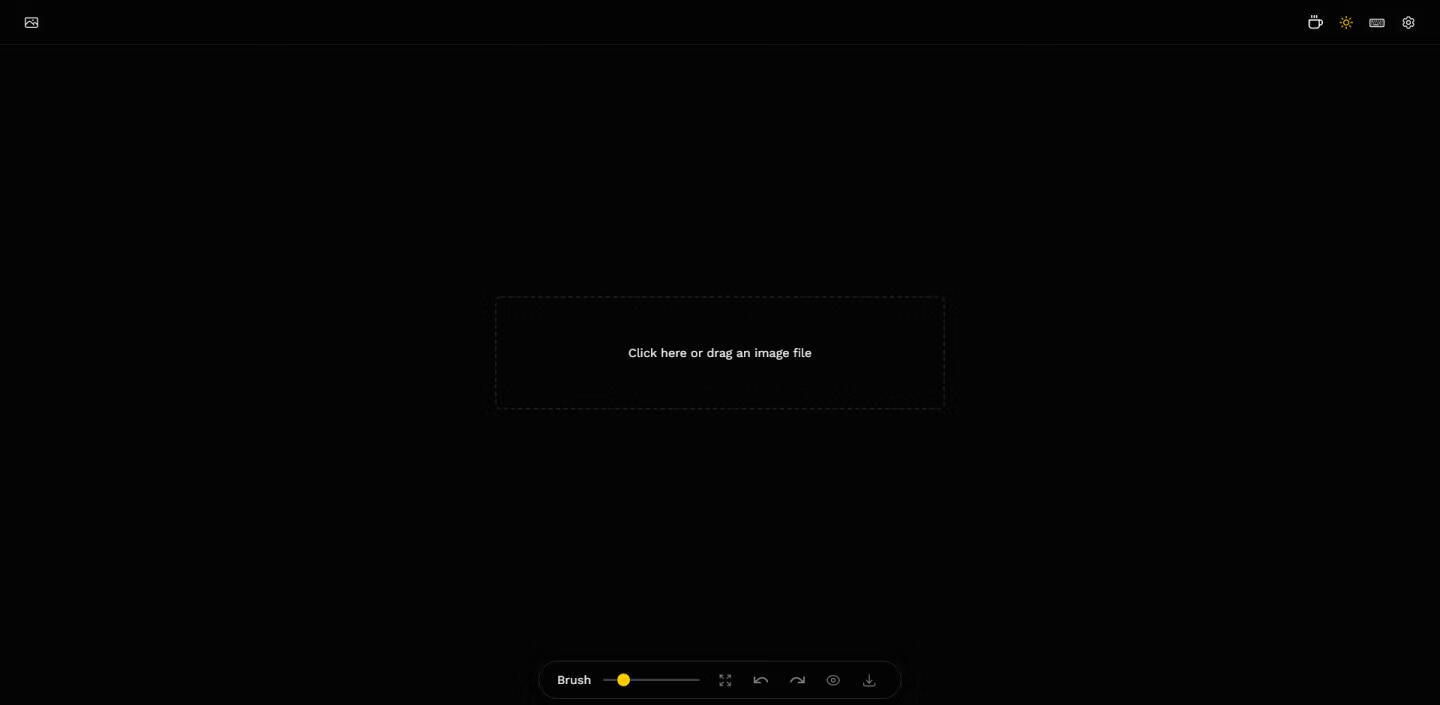
Lama Cleaner – 图片视频一键去水印、去人物、去背景AI工具,本地整合包
这是一款 AI 修复神器,对于照片中不想要的东西,我们只需要简单涂抹,后台就会自动抹去对应的部分且尽量让抹去的部分和周围的环境相融合。比如想去个图片的水印,自拍照去掉背景中杂乱的人物或...
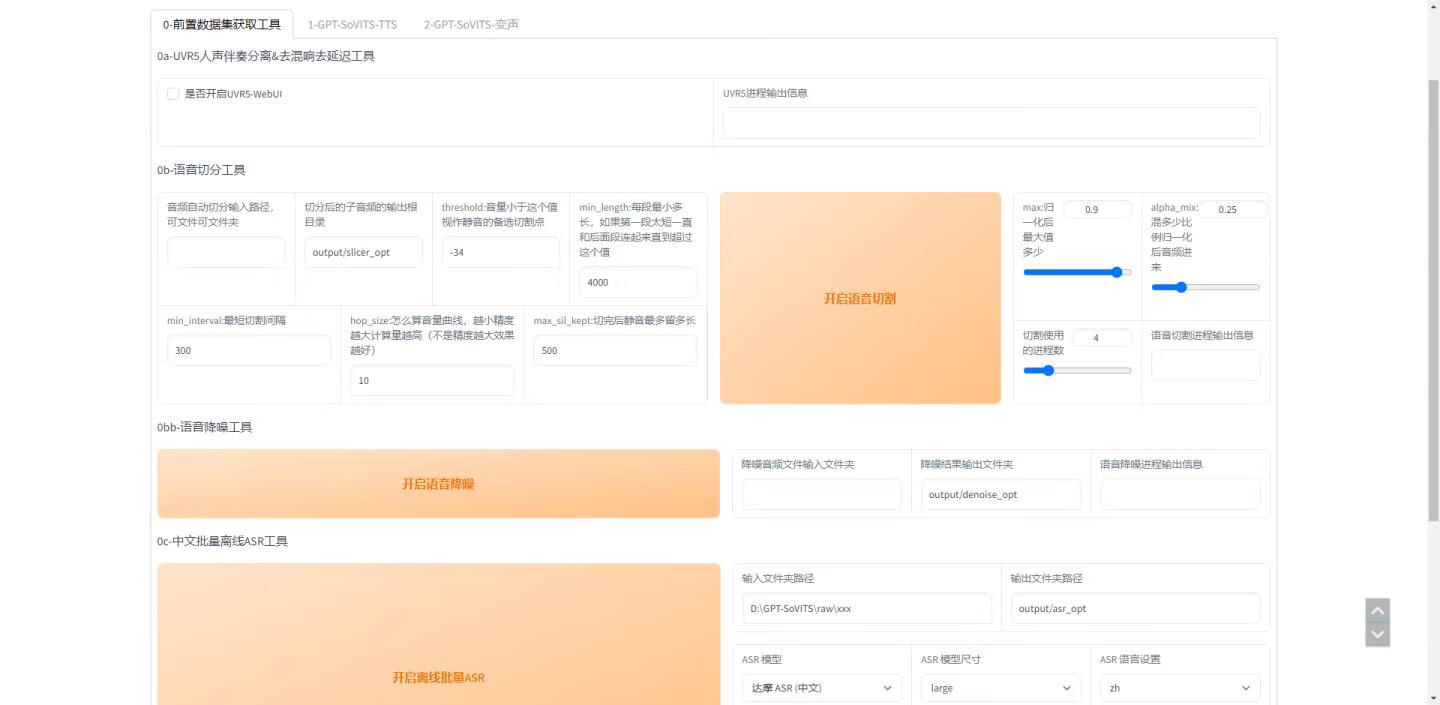
GPT-SoVITS声音克隆中文一键整合包:只需要5秒语音就能模仿你
今天我要给大家介绍一款高效好用的AI语音TTS项目:GPT-SoVITS只需5秒的数据,它就可以文本到语音的转换!只需1分钟的声音数据,就可以训练出一个克隆你的声音的TTS模型!下面是它的效果展示: ...

AI音乐创作,MusicGen一键整合包,创作属于自己的音乐
AI音乐创作,MusicGen一键整合包,创作属于自己的音乐,操作简单,生成效果不错,音乐无版权,可以直接拿来使用。 制作属于自己的专属配音 这个软件要求的电脑也不低,内存建议16G-32G,显存8G...

DiffSynth-Studio视频风格转绘一键就能三渲二【带完整视频教程】
DiffSynth 是一个新的扩散引擎。我们重构了文本编码器、UNet、VAE等架构,保持与开源社区模型的兼容性,同时增强计算性能。该版本目前处于初始阶段,支持SD和SDXL架构。未来,我们计划基于这个...


Arc2Face 一键整合包 + 整合包制作教学
只需几秒钟,批量生成超高质量主题的AI人脸艺术风格照,完美复制人脸,太像了!𝐀𝐫𝐜𝟐𝐅𝐚𝐜𝐞 :一种新的人脸基础模型,支持本地执行,可以试试↓ Arc2Face特点:1. 给定 ArcFace 嵌入,Arc...
