 逃课猫
逃课猫
APISR一键整合包 专注二次元动漫图像视频分辨率增强,无损放大AI神器
APISR – 专注二次元动漫图像分辨率增强,无损放大AI神器,让漫画焕然一新,动漫爱好者的福音APISR 是一个新的放大算法,专门用于恢复和增强各种低质量、低分辨率的动漫图像和视频,其模型代码...
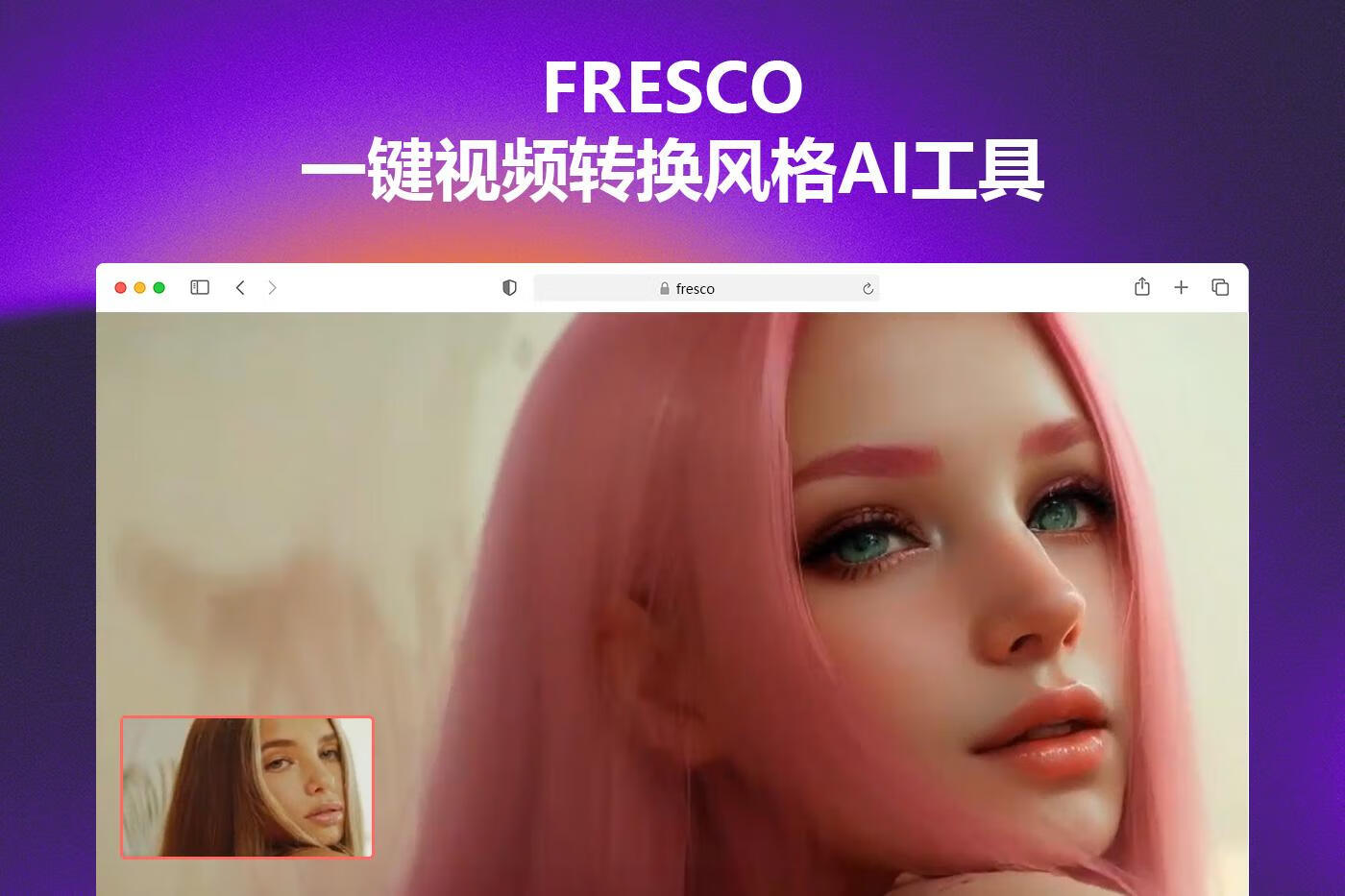
FRESCO 视频风格化转换| 一键整合包风格转换AI工具
FRESCO:只需文字提示即可轻松将视频转换成各种风格FRESCO能够在不需要额外训练的情况下,直接对视频进行编辑和风格转换同时保留视频动作和情节的自然流畅。确保视频中的每个元素(如人物、物体...

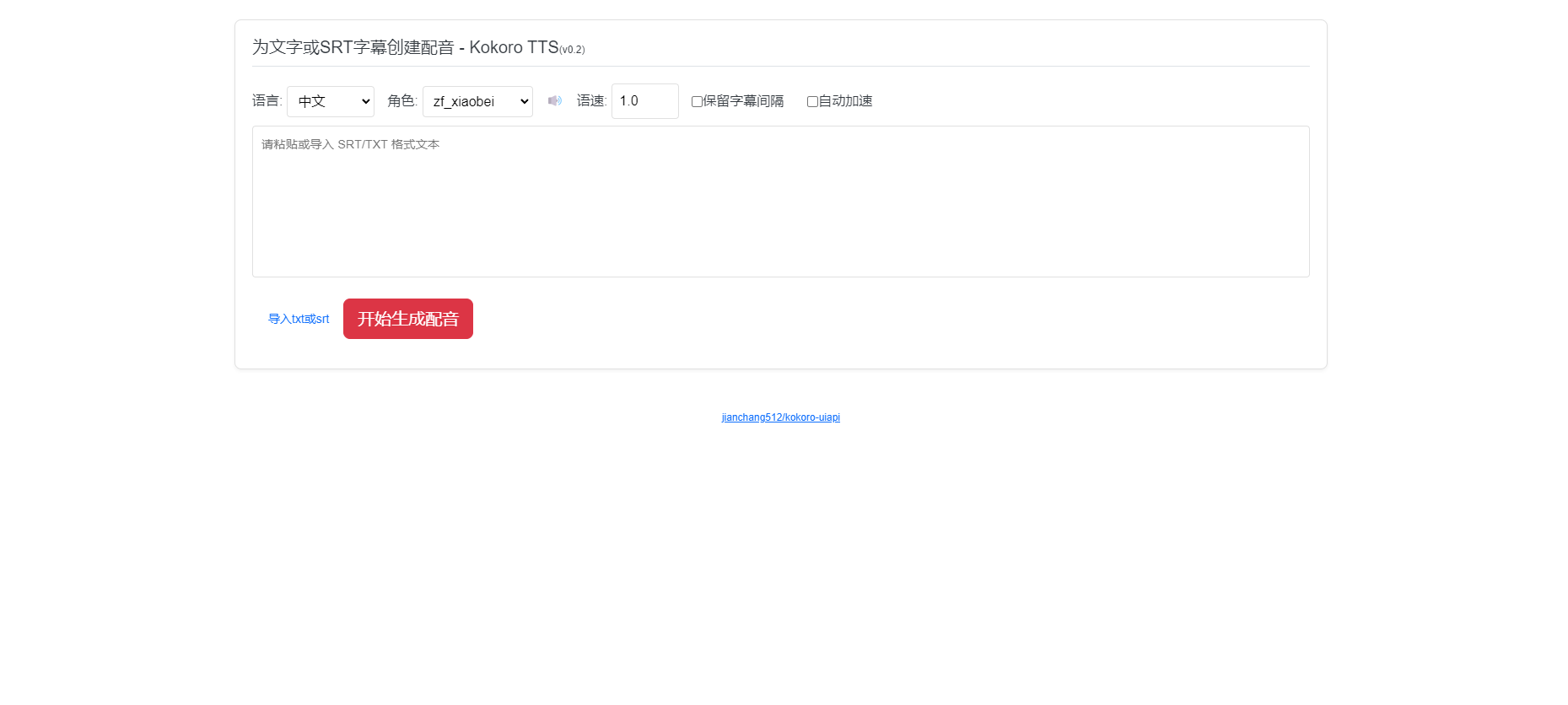
为文字或SRT字幕创建配音-一键整合包
随着人工智能的不断进步,文本转语音(TTS)技术已经成为我们日常生活中不可或缺的一部分。 从语音助手到有声读物,再到角色配音,TTS 的应用场景日益广泛。 然而,尽管市面上已有众多 TTS 模型...
 会员专属
会员专属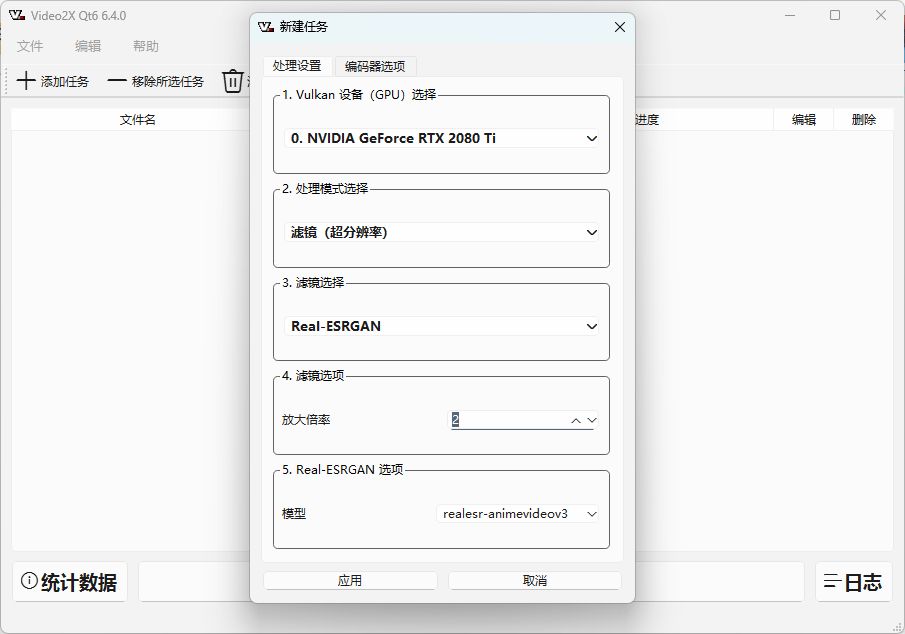
无损放大软件-支持放大补帧,速度快效明显
是一款可以无损提高画质的软件,这个软件对于一些想自己制作高清视频的用户来说是不错的选择,软件操作起来还是蛮复杂的,有需要的用户可以下载研究体验一下,支持批量操作,节省时间。 放大效...


【绿色版 DragGAN】图像流编辑 | 支持自定义图片 | 一键操作
在图片上设定关键点,AI自动补全,图片就可以按照你想要的意图去改变,你的心有多大,世界就有多大,一切变化都在你的想象之间。1.3版支持自定义图片上传! 如果你是一个喜欢拍照编辑图像的人,...
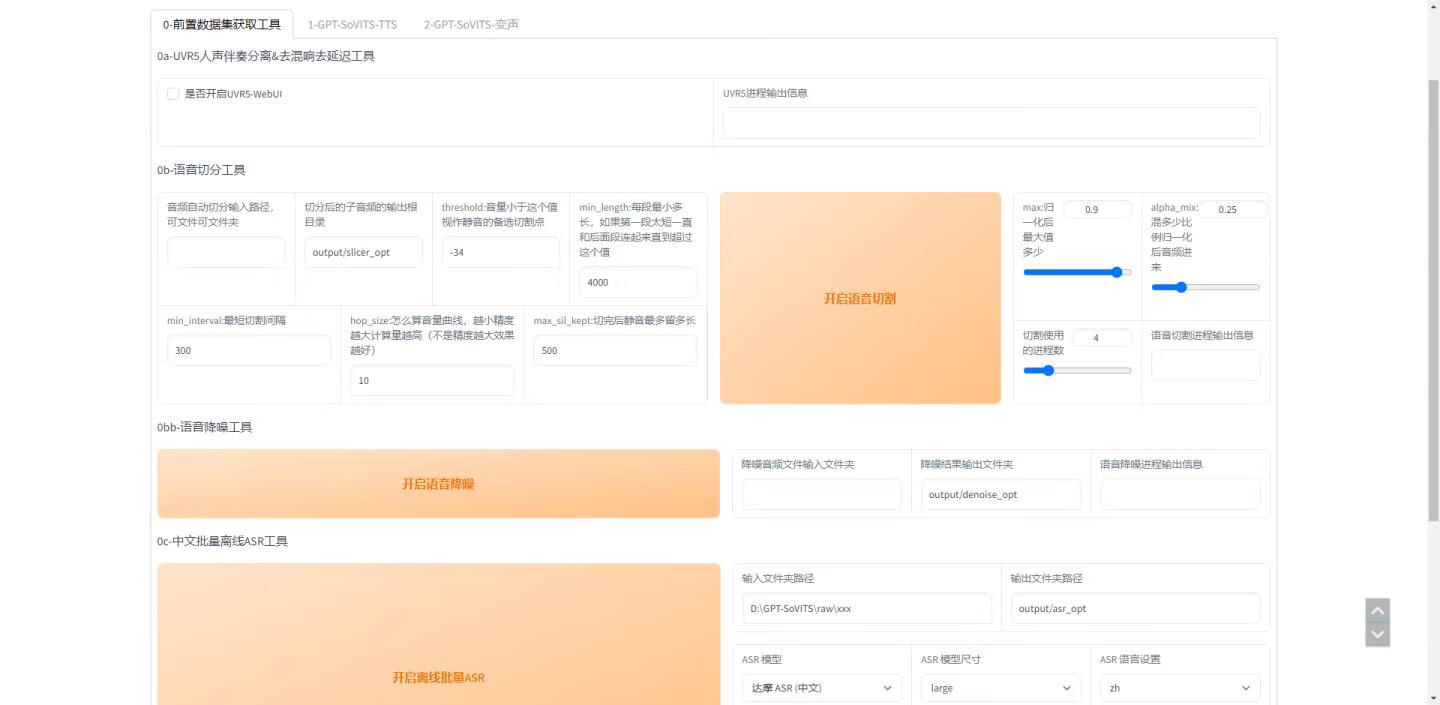
GPT-SoVITS声音克隆中文一键整合包:只需要5秒语音就能模仿你
今天我要给大家介绍一款高效好用的AI语音TTS项目:GPT-SoVITS只需5秒的数据,它就可以文本到语音的转换!只需1分钟的声音数据,就可以训练出一个克隆你的声音的TTS模型!下面是它的效果展示: ...

DeepFaceLab官方遮罩教程使用方法“ whole_face” + XSeg
这个是官方最标准的一个视频教程,建议新手认真观看,理解其中的内容,不要小看了哦。很多主要的都介绍了,虽然全程没有讲解。
