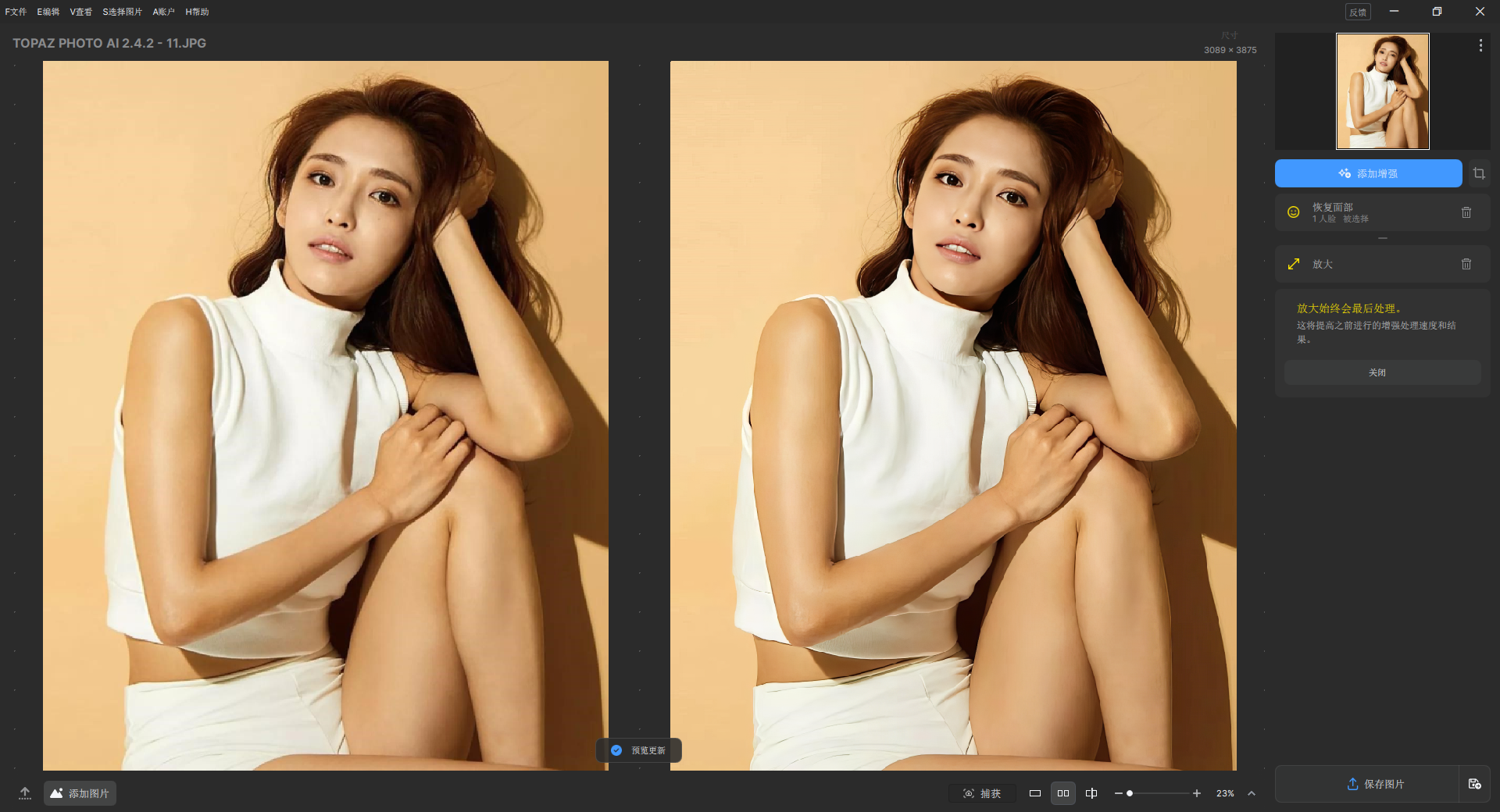
Whisper-WebUI 是一款基于 OpenAI Whisper 语音识别模型的开源桌面应用。
它提供了一个图形化用户界面,旨在简化音视频内容的转录流程,能够自动生成带时间戳的字幕文件。 该工具支持多种输入源,包括本地音视频文件、YouTube 视频链接以及麦克风实时录音。
此外,它还集成了文本翻译和背景音乐分离等辅助功能,为用户提供了一套完整的音频处理解决方案。
![图片[1]-Whisper-WebUI视频翻译字幕生成一键整合包-逃课猫Deepfacelab|AI智能研究站](https://wkphoto.bj.bcebos.com/0d338744ebf81a4c2c03669fc72a6059252da6b7.jpg)
![图片[2]-Whisper-WebUI视频翻译字幕生成一键整合包-逃课猫Deepfacelab|AI智能研究站](https://wkphoto.bj.bcebos.com/ac4bd11373f082027a801b695bfbfbedab641b51.jpg)
文件(File):处理本地音视频文件。
YouTube:处理 YouTube 视频链接。
麦克风(Mic):进行实时语音录制与转录。
T2T 翻译(T2T Translation):翻译字幕文件。
BGM 分离(BGM Separation):分离音轨中的人声和背景音乐。
本地音视频转录文字(File)
点击上传区域,选择需要处理的音视频文件。
在模型(Model)下拉菜单中选择转录模型(例如,V3 模型在准确性上表现更优)。
在语言(Language)菜单中指定源文件的语言。
选择期望的文件格式(File Format),如 SRT。
点击生成字幕文件(GENERATE SUBTITLE FILE)。
任务完成后,可在左侧预览窗口查看结果,支持将字幕文件保存至本地。
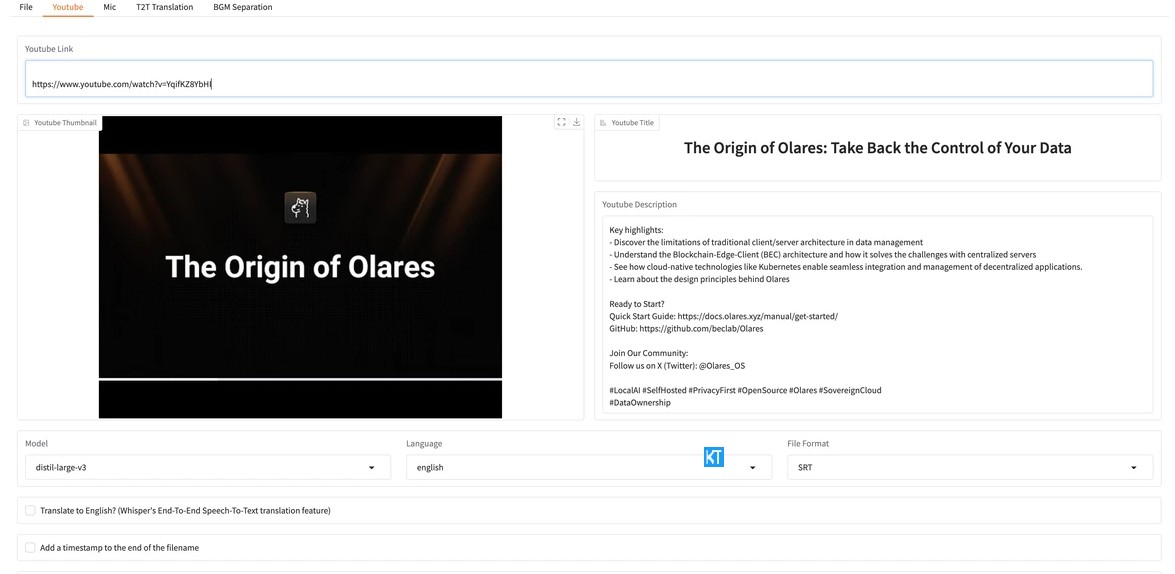
YouTube 视频转录(YouTube)
将目标 YouTube 视频的 URL 粘贴到输入框中。 Whisper-WebUI 将自动识别视频的封面、题目和视频简介。
- 上传需要处理的音频文件。
- 根据硬件情况选择设备(Device),如使用 NVIDIA 显卡可选择 CUDA。
- 选择分离模型,分段大小默认 。
- 点击分离背景音乐(SEPARATE BACKGROUNS MUSIC)。
处理完成后,可下载分离出的人声和背景音文件。
1、该资源仅供学习和研究传播,大家请在下载后24小时内删除,一切关于该资源商业行为与逃课猫智能研究站(taokemao.cn)无关。
2、请勿将该软件程序进行商业交易、转载、违法运营等行为,该软件只为研究、学习所提供,该软件程序使用后发生的一切问题与本站无关。
3、若本程序源/码侵犯了您的权益,请及时联系我们予以删除!
4、本程序仅供研究学习使用,切勿商用以及违法使用!
5、本站收费内容,只用于维持域名注册、网页空间租用等费用日常开销。
6、本站免费、含会员内容的软件工具,皆不包含人工技术服务教程等服务,大部份已提供视频教程,请自行网上搜索。