 逃课猫
逃课猫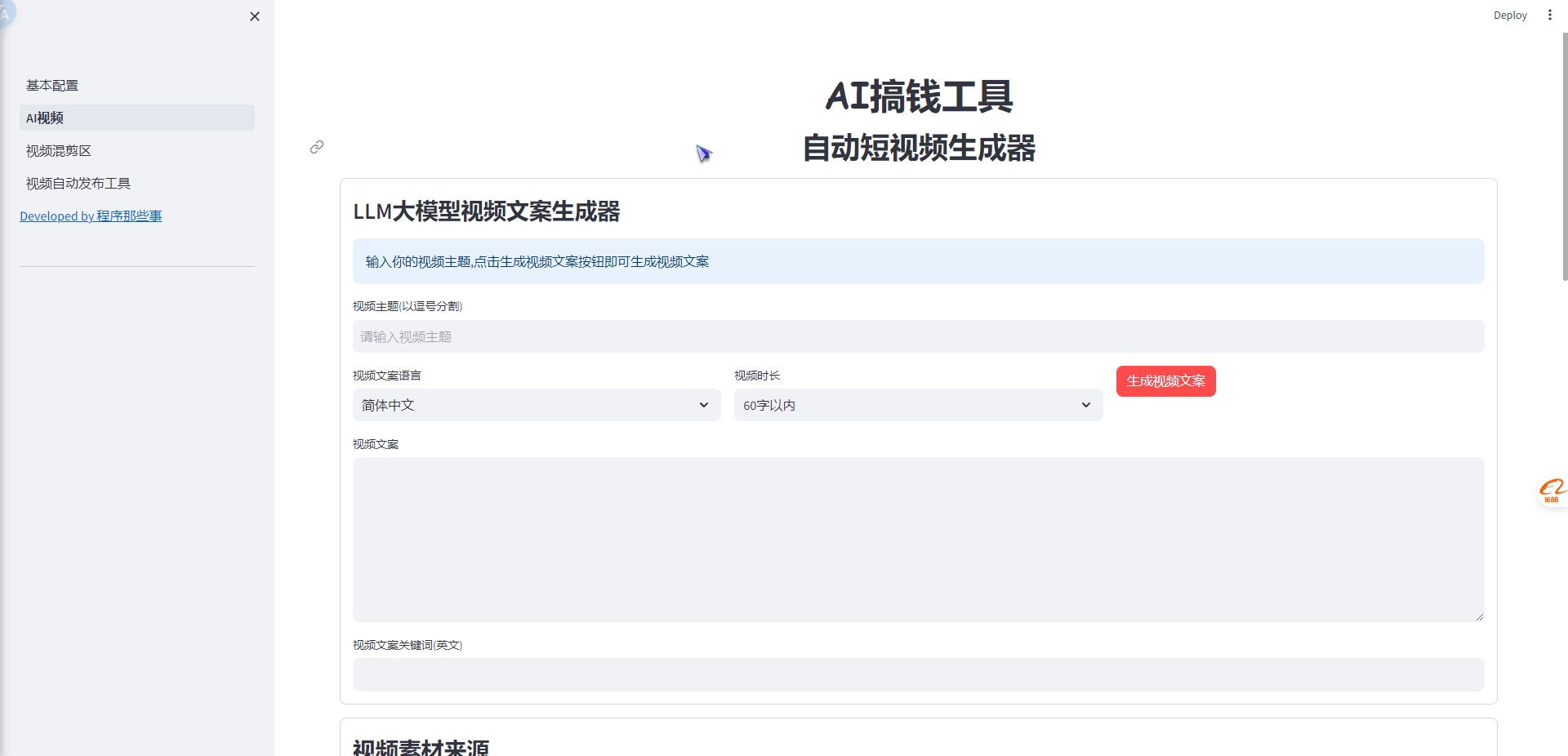
AI视频混辑工具整合包
它可以:使用AI大模型技术,一键批量生成各类短视频。它可以:一键混剪短视频,批量生成短视频不是梦。它可以:自动把视频发布到抖音,快手,小红书,视频号上。支持本地语音模型chatTTS, fasterwhi...

【绿色版 DragGAN】图像流编辑 | 支持自定义图片 | 一键操作
在图片上设定关键点,AI自动补全,图片就可以按照你想要的意图去改变,你的心有多大,世界就有多大,一切变化都在你的想象之间。1.3版支持自定义图片上传! 如果你是一个喜欢拍照编辑图像的人,...



IDM-VTON | AI一键完美换装,商用级效果,支持上衣,裤子,裙子多种替换!
IDM-VTON | AI一键完美换装,商用级效果,支持上衣,裤子,裙子多种替换!软件对电脑配置要求过高,只支持N卡,Windows系统,内存16G以上 IDM-VTON(Virtual Try-on)是一个基于深度学习的虚...

Firered-image-edit1.1小红书人物换装一键整合包
小红书Super Intelligence团队推出图像编辑模型FireRed-Image-Edit-1.1 距其1.0版本发布不到一个月。据该团队介绍,该模型在处理ID一致性编辑、多元素融合、人像美妆、字体风格参考等方面大幅提...

人声分离本地离线版整合包,无需联网
这是一个极简的人声和背景音乐分离工具,本地化网页操作,无需连接外网,使用 2stems/4stems/5stems 模型。 将一首歌曲或者含有背景音乐的音视频文件,拖拽到本地网页中,即可将其中的人声和音...
 会员专属
会员专属
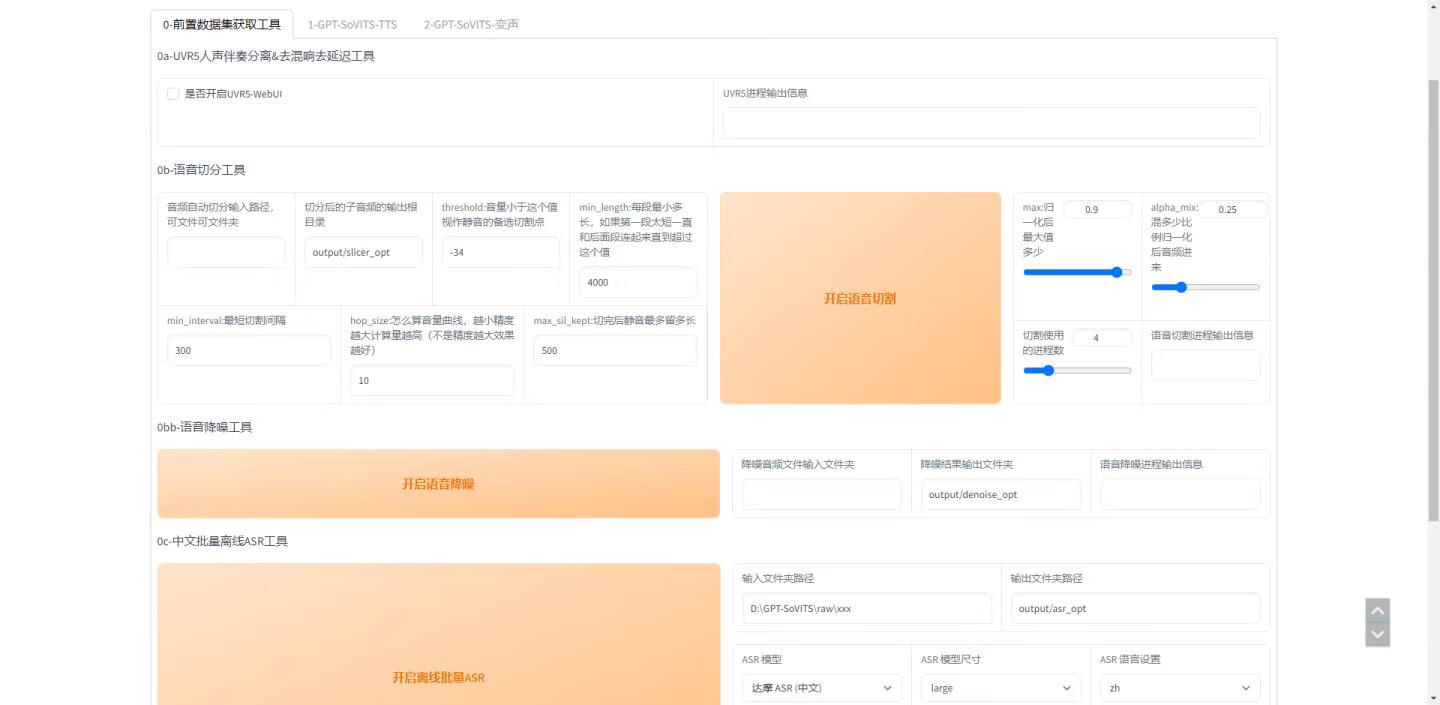
GPT-SoVITS声音克隆中文一键整合包:只需要5秒语音就能模仿你
今天我要给大家介绍一款高效好用的AI语音TTS项目:GPT-SoVITS只需5秒的数据,它就可以文本到语音的转换!只需1分钟的声音数据,就可以训练出一个克隆你的声音的TTS模型!下面是它的效果展示: ...

DiffSynth-Studio视频风格转绘一键就能三渲二【带完整视频教程】
DiffSynth 是一个新的扩散引擎。我们重构了文本编码器、UNet、VAE等架构,保持与开源社区模型的兼容性,同时增强计算性能。该版本目前处于初始阶段,支持SD和SDXL架构。未来,我们计划基于这个...
