最新发布
排序
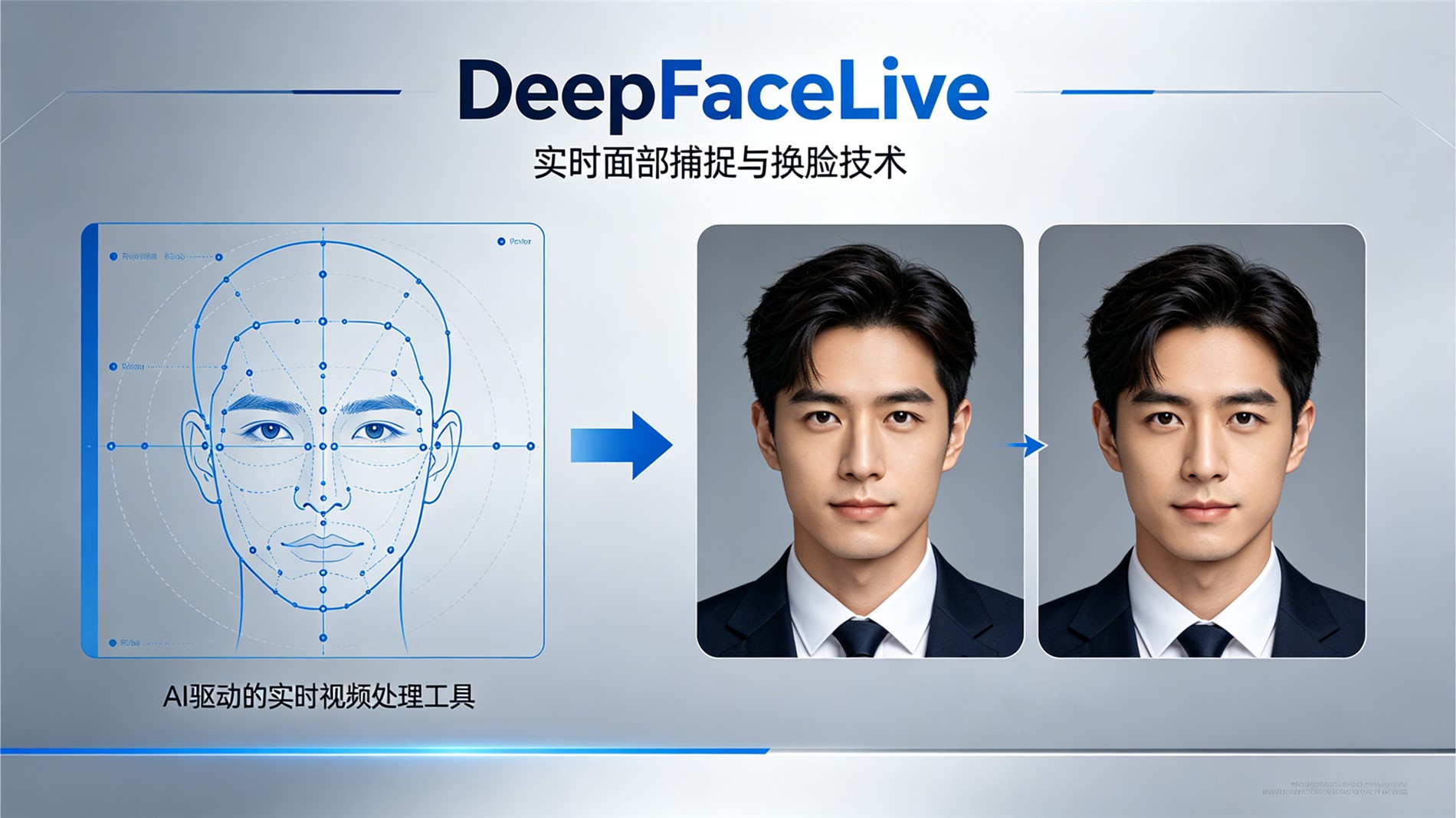
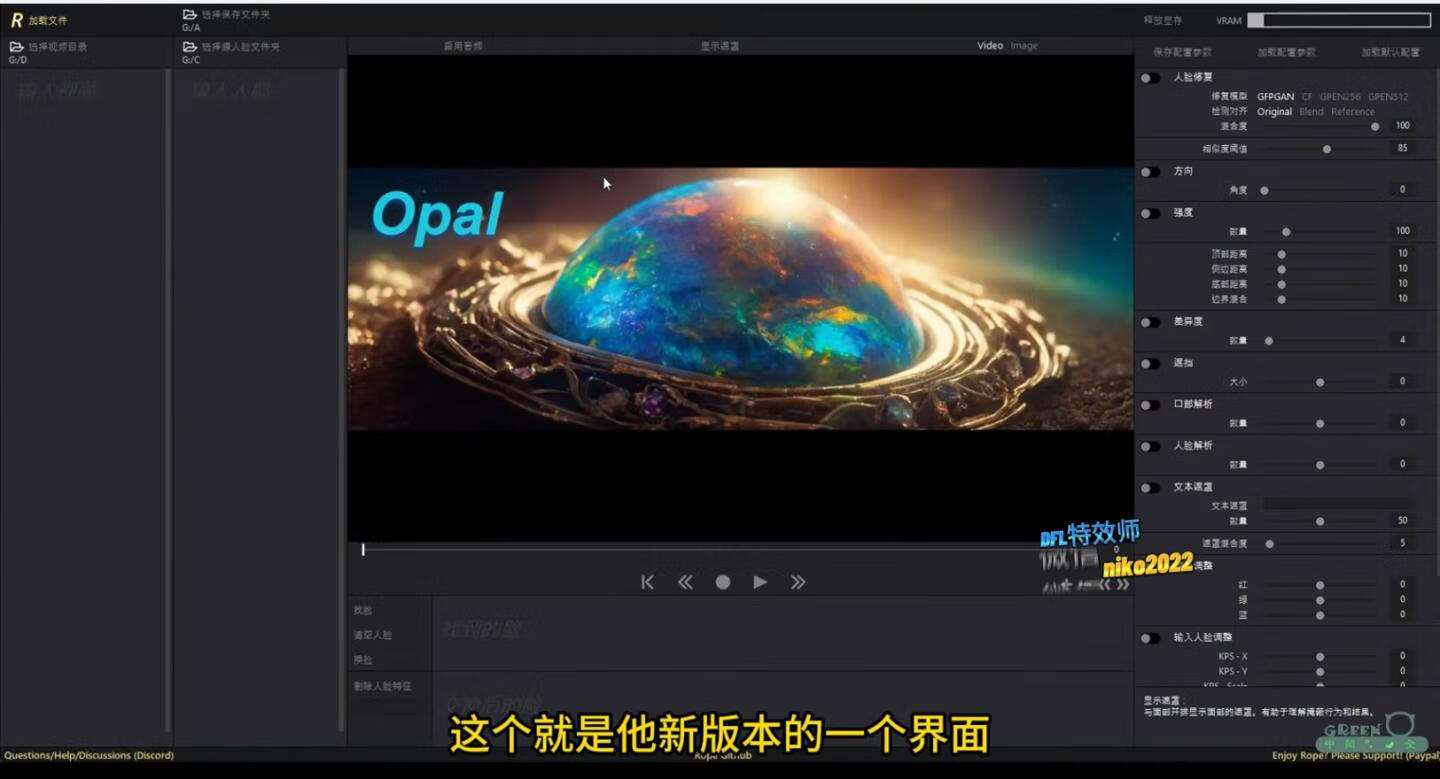
DeepFaceLive_NVIDIA-2026最新汉化直播|稳定|流畅
这个版本目前最新汉化版的直播换脸专用 ,不懂的不要下,不提供技术支持和教程,请自行网上查找资料。 如需提供相应的配套模型和教学请联系微信。
 会员专属
会员专属

DeepFaceLab官方遮罩教程使用方法“ whole_face” + XSeg
这个是官方最标准的一个视频教程,建议新手认真观看,理解其中的内容,不要小看了哦。很多主要的都介绍了,虽然全程没有讲解。

deepfacelabs最新版影视AI换脸软件11.20.2021
这个软件已基本不更新了,目前最版为11.20.2021,更新内容以下》============ CHANGELOG ============== 20.11.2021 ==Fixed rct color transfer in mergerFixed model export.== 20.10.2021 ==...

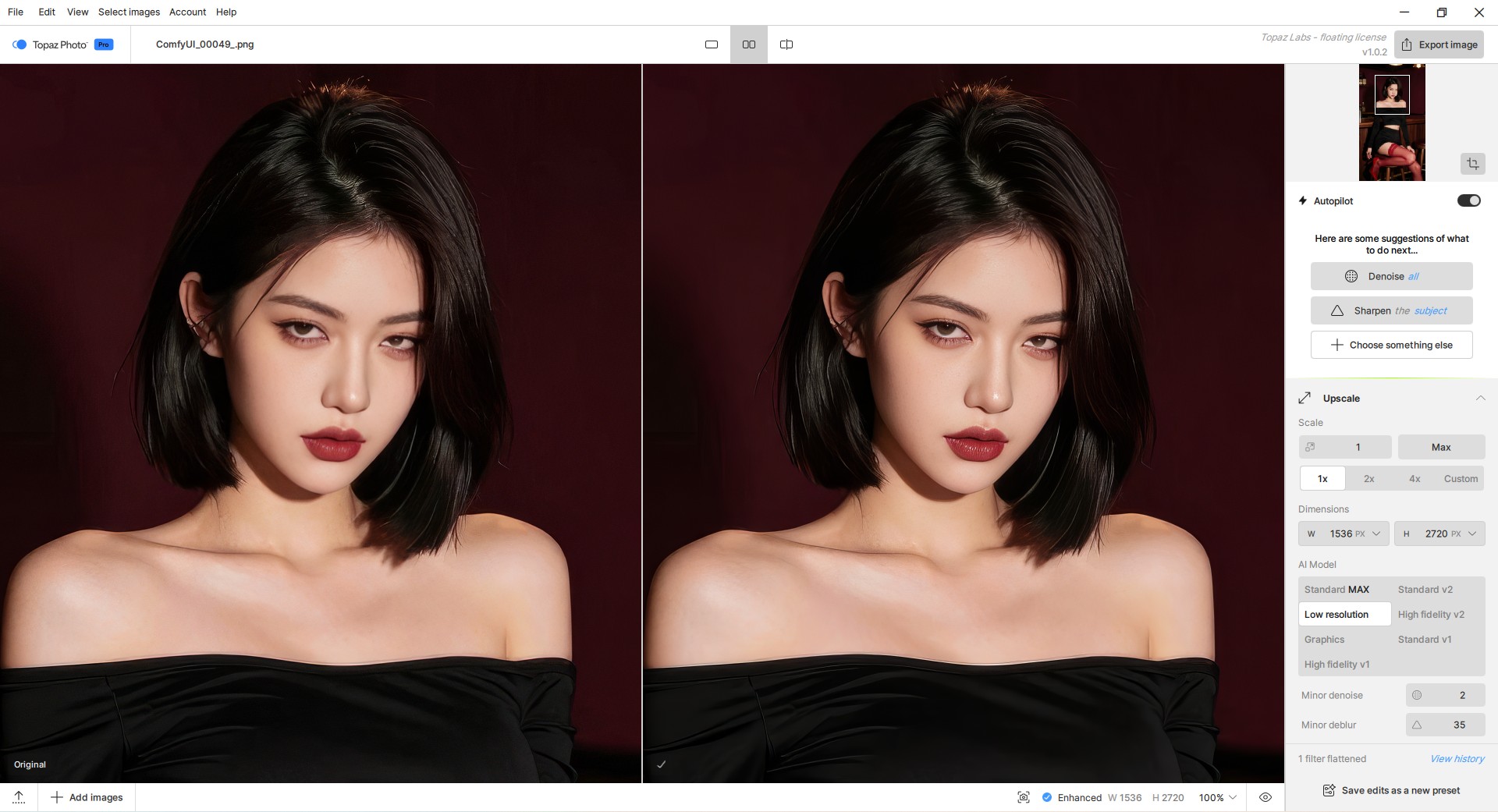
Topaz Photo(图像增强软件) Pro v1.0.3绿色版+MODEL模型
Topaz Photo 是 Topaz Labs 推出的最新图像增强软件,主打 AI 驱动的画质优化,能满足摄影爱好者与专业人士的基础修图需求,操作高效且效果精准。它集合了之前软件 Denoise AI、Sharpen AI、Gig...

文字转语音神器!拥有真人般的语音效果!处理大量文字也不是问题!快速介绍两款强大的AI工具
文字转语音神器!拥有真人般的语音效果!处理大量文字也不是问题!快速介绍两款强大的AI工具 本文介绍了两款好用的免费文字转语音AI工具。第一款工具,界面简洁,提供多种语言和发音角色选择,...
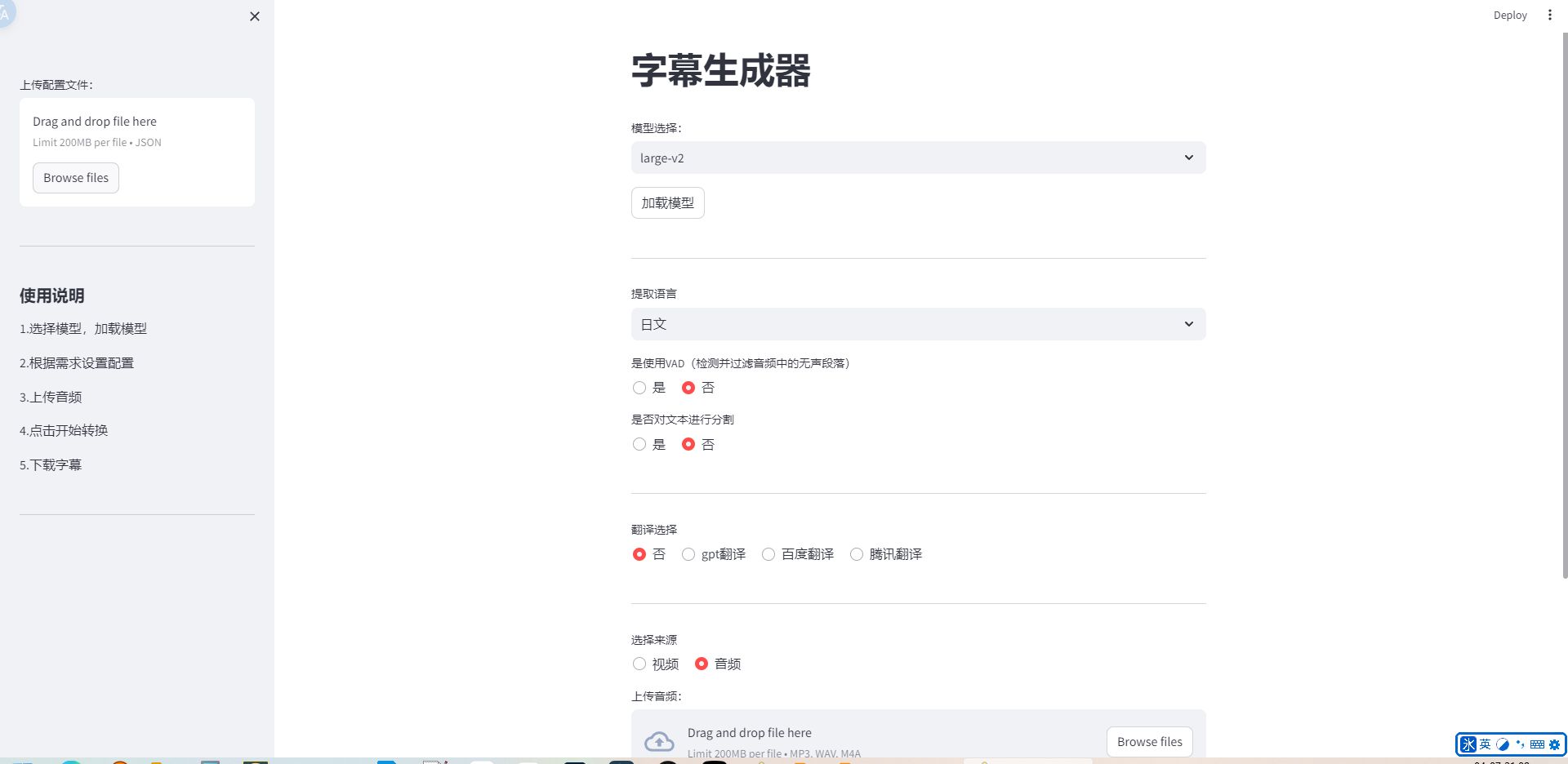
自动字幕生成器一键包
Auto-Subtitle 是由 m1guelpf 创建的一个 Python 库,它可以集成到视频处理工作流程中,自动分析视频音频,生成相应的文字字幕。这个项目的目标是简化创建视频字幕的过程,提高效率,并通过开放...


 会员专属
会员专属
全自动录播、工具 支持B站抖音快手虎牙youtube等主流直播整合包
是一组工具集,旨在降低使用、开发自动化b站投稿的难度,同时提供了b站web端、客户端投稿工具未开放的一些功能,如多p投稿,线路选择,并发数设置,直播录制,视频搬运等. 录制各大主流直播平台...
